

データストリーミングのパイオニアであるConfluentは、先月ニューオーリンズで開催された年次イベント「Current New Orleans 2025」で、AI時代の大きな障壁となっている「コンテキスト不足」を解消する新製品群と、DSP(データストリーミングプラットフォーム)の大幅な強化を発表した。
同イベントにあわせて、今月14日には報道関係者向けのメディアラウンドテーブルも実施され、ConfluentおよびConfluent Japanの最新動向に加えて、「Current New Orleans 2025」で発表された内容があらためて紹介された。日本法人としての視点や解釈も交えながら、新製品群の特徴が語られている。
リアルタイムAIを駆動する「Confluent Intelligence」
Confluentは、「Apache Kafka」を基盤とするデータストリーミングプラットフォームを提供する米国企業で、クラウド版の「Confluent Cloud」やオンプレミス向けの「Confluent Platform」を展開している。
2014年にKafkaの共同創作者らが設立し、2025年時点で同社の時価総額は約81億ドル、年間サブスクリプション収益は11億ドル前後と見込まれ、データストリーミング市場における主要企業の一つとなっている。
一方で、競合環境は厳しい。AWSのMSKやGoogle CloudのDatastreamは価格やエコシステム統合で優位性を持ち、RedpandaやStreamNative(Pulsarベース)などの新興勢も性能やコスト面で存在感を高めている。
総じて、ConfluentはKafkaの強みを活かしたエンタープライズ向けの地位を維持しているが、クラウドネイティブ化とコスト競争が進む中で、シェアの変動や代替技術の台頭も続いている。そんな市況環境の中、ConfluentはAI時代に不可欠となる「リアルタイムのコンテキスト供給」を次の成長軸と位置づけ、イベント駆動型AIを支える基盤として自社DSPを再定義しようとしている。
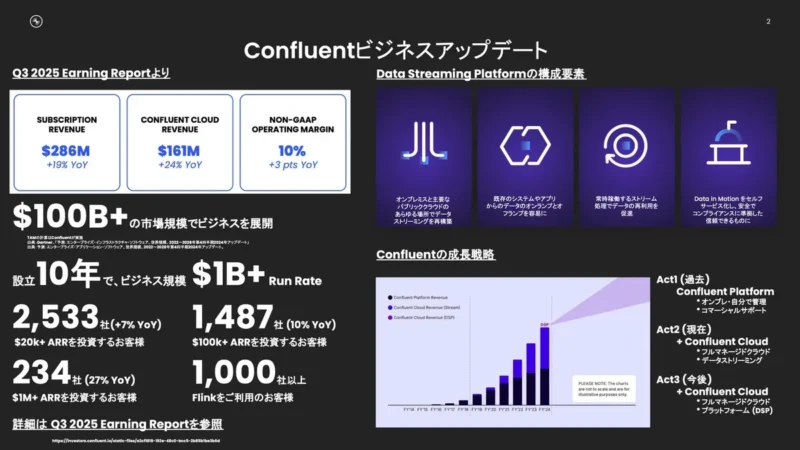
Confluent Japanのカントリーマネージャーである石井光一氏は、データストリーミング市場がすでに1000億ドル(約15兆円)規模に達していると説明する。同社は創業10年で年間収益ランレート10億ドル(約1500億円)に到達するまでに成長した。国内では、データストリーミングの具体的な活用を検証する企業が増えており、特に特定ユースケースにひもづいた本番適用の検討が進んでいるという。
一方で、生成AIへの投資は3000億〜4000億ドルに達しているものの、その取り組みの95%が成果につながっていないという調査もある。最大要因は、AIの推論に不可欠な「最新で信頼できる情報=コンテキスト」が不足している点だ。

Confluentはこの課題に応えるため、イベント駆動型AIシステムを構築・拡張できる統合プラットフォーム「Confluent Intelligence」を展開する。同社はAIエージェントを、イベントを介して連携する「マイクロサービスの進化形」と捉えており、それらを動かす基盤として、KafkaとFlinkをフルマネージドで提供していく方針を示している。
「Confluent Intelligence」の中核を担う主な要素は次のとおりだ。
- Real-Time Context Engine
AIエージェントやアプリケーションに対し、リアルタイムに構造化された高品質なコンテキストを提供するフルマネージドサービス。Kafkaの運用を意識せずとも、最新の信頼できるデータに直接アクセスできる。 - Streaming Agents
Apache Flink上で、イベント駆動型AIエージェントをネイティブに構築・展開・オーケストレーションする機能。データ処理とAI推論を統合し、エージェントがリアルタイムで観察・判断・行動できる。AnthropicのClaudeがデフォルトLLMとして組み込まれる予定だ。 - 組み込みML関数
Flink SQLで、異常検知・予測・不正検知といったデータサイエンスのタスクを簡潔に扱える。モデル構築や専門知識がなくても、流れ続けるデータに対するリアルタイム分析を実現する。
DSPの基盤強化:ガバナンス、セキュリティ、分析連携を拡張
AI機能の発表と並行し、Confluentはストリーミング基盤そのものの強化にも取り組む。DSPは、ストリーム(Kafka)/処理(Flink)/連携(CONNECT)/ガバナンス(GOVERN)の4本柱から構成され、データが生成された瞬間から加工・品質保証まで一貫して扱うことを目指しており、「Current 2025」ではその中でもエンタープライズ運用を支える機能が重点的にアップデートされた。
1. Confluent Private Cloud (CPC)

Confluent Private Cloud(CPC)は、オンプレミスでの運用を必要とする組織に向け、クラウドネイティブな自動化やパフォーマンス、管理性をそのまま提供するためのソリューションだ。
- クラウド技術をオンプレミスへ移植
Confluent Cloudで使われるKafka拡張基盤「KORAエンジン」の機能が、オンプレミスのConfluent Platformでも利用可能となる。 - ガバナンスの一元管理
「Unified Stream Manager(USM)」アドオンにより、Cloudとオンプレミス双方でのスキーマ管理、データトラッキング、コンプライアンスを統合管理できる。
2. Tableflowサービスの拡張

Tableflowは、KafkaのトピックをApache IcebergやDelta Lakeといったオープンテーブル形式に変換し、データウェアハウスや分析エンジンへ届けるサービスだ。ETLの簡略化や統合自動化を実現し、ストリーミングデータと分析基盤のギャップを埋める。
今回のアップデートでは、特に大規模企業の本番運用を想定した機能が強化された。
- Delta Lake/Unity Catalogとの統合GA
マルチクラウド環境での運用がより容易になった。 - Upsertのサポート
データの変更に応じて自動的に更新・挿入し、整合性を維持する。 - Dead Letter Queues(DLQ)対応
不正データを隔離しつつデータフローを止めない仕組みを提供する。 - BYOK対応
顧客管理の暗号鍵を利用することで、保存データへのコントロールを強化する。
データ品質とガバナンスの強化
Confluentのガバナンス機能は、データ品質とコンプライアンスの担保に重点を置いている。特に、以下の二段階バリデーションが特徴的だ。
- スキーマバリデーション
流れてくるデータが定義済みスキーマに一致しているかを自動でチェックする。Kafka Connectと組み合わせることでスキーマ登録を効率化できる。 - 文脈的バリデーション
スキーマ上は正しくても、「8桁の英数字が必要」といった文脈ベースのルールを満たしているかを確認する。現時点では顧客がルールを定義する必要がある。
今回のアップデート群は、「AI時代のデータ基盤とは何か」という問いに対するConfluentなりの解答を提示したものと言える。データはもはや蓄積するだけでは価値を生まない。生成される瞬間から品質が担保され、リアルタイムに流通し、あらゆるAIとアプリケーションがその「文脈」を直接利用できる形で届けられる必要がある。
その前提が整ってはじめて、AIは企業の意思決定や業務プロセスの中で「常時稼働するエンジン」として機能する。Confluentが目指しているのはまさにその基盤であり、Kafka/Flink/ガバナンス/オープンテーブル形式のすべてを一つのストリーミングプラットフォームに統合しようとする姿勢は、データ基盤ベンダーの中でも際立っている。データストリーミング市場が急成長する中で、同社は「AIを動かすための血流を誰が担うのか」という競争の中心に立ちつつある。


(画像:Confluent Japan)

